流式,Agent 的神经系统
最近在做一个 Agent 项目,给它的执行流程补上流式输出能力。流式会穿透消息模型、循环控制和会话持久化,远比改一个 API 参数复杂。下面是这次实现过程的总结。
一、协议分层
循环抽象由自己实现:预算检查、事件钩子、工具执行、重试、错误分类这些决定,通用框架的循环黑盒塞不进来。流式接口必须服务于我们自己的循环。
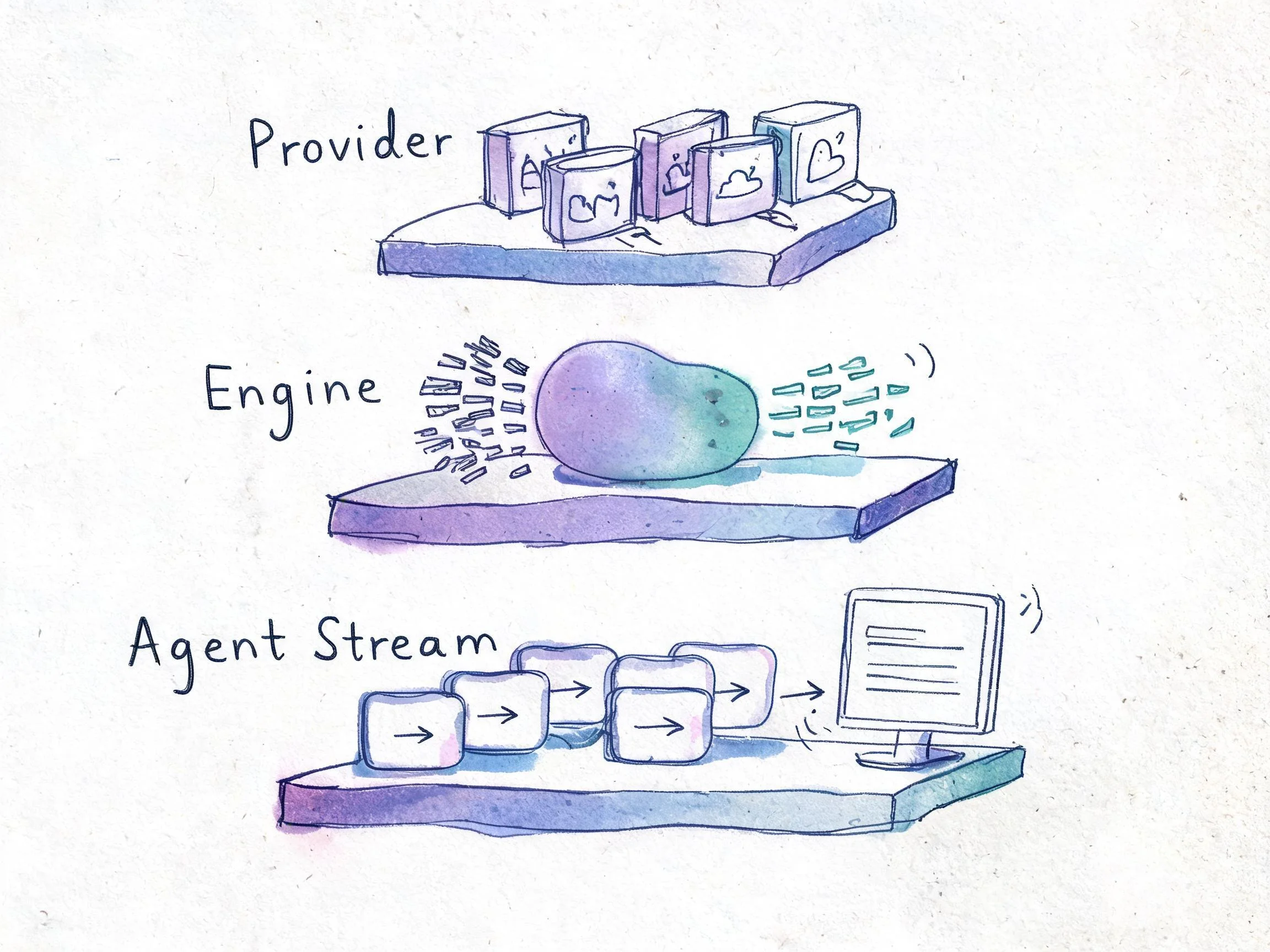
流式被拆成三层:
- Provider 层:把 OpenAI、Anthropic 等 SDK 的原始流解析成统一的
StreamChunk; - Engine 层:在推理引擎的
infer里归一化,并处理 reasoning 标签分区; - Agent Stream 层:把 chunk 加工成带边界的输出块(
OutputChunk),供 UI 消费。
统一的 chunk 类型大致是:
export type StreamChunk =
| { type: 'text'; text: string }
| { type: 'reasoning'; text: string }
| { type: 'tool-call'; toolCallId: string; toolName: string; input: unknown }
| { type: 'usage'; inputTokens: number; outputTokens: number; totalTokens: number }
| { type: 'finish'; reason: string };OpenAI provider 把 delta.content、delta.tool_calls、chunk.usage 映射进来;Anthropic provider 处理 text_delta、thinking_delta、tool_use。不同 SDK 的协议差异被压在这一层。
Engine 层还处理了 thinking 标签。有些模型把推理内容混在普通 text 里,用 XML 风格的标签包裹。Engine 里需要一个分区器把 text 切成 text 和 reasoning 两类 chunk,UI 才能区分思考和回答。
二、多轮 Loop:多个 message,还是单个 message?
循环里要支持多步 ReAct:一次用户输入,模型可能先调用工具,拿到结果后继续推理,再调用工具,直到输出最终答案。这由一个 turn runner 用 while 循环驱动,每轮调用一次 loop 策略,并通过 step 边界标记记录步骤起止。
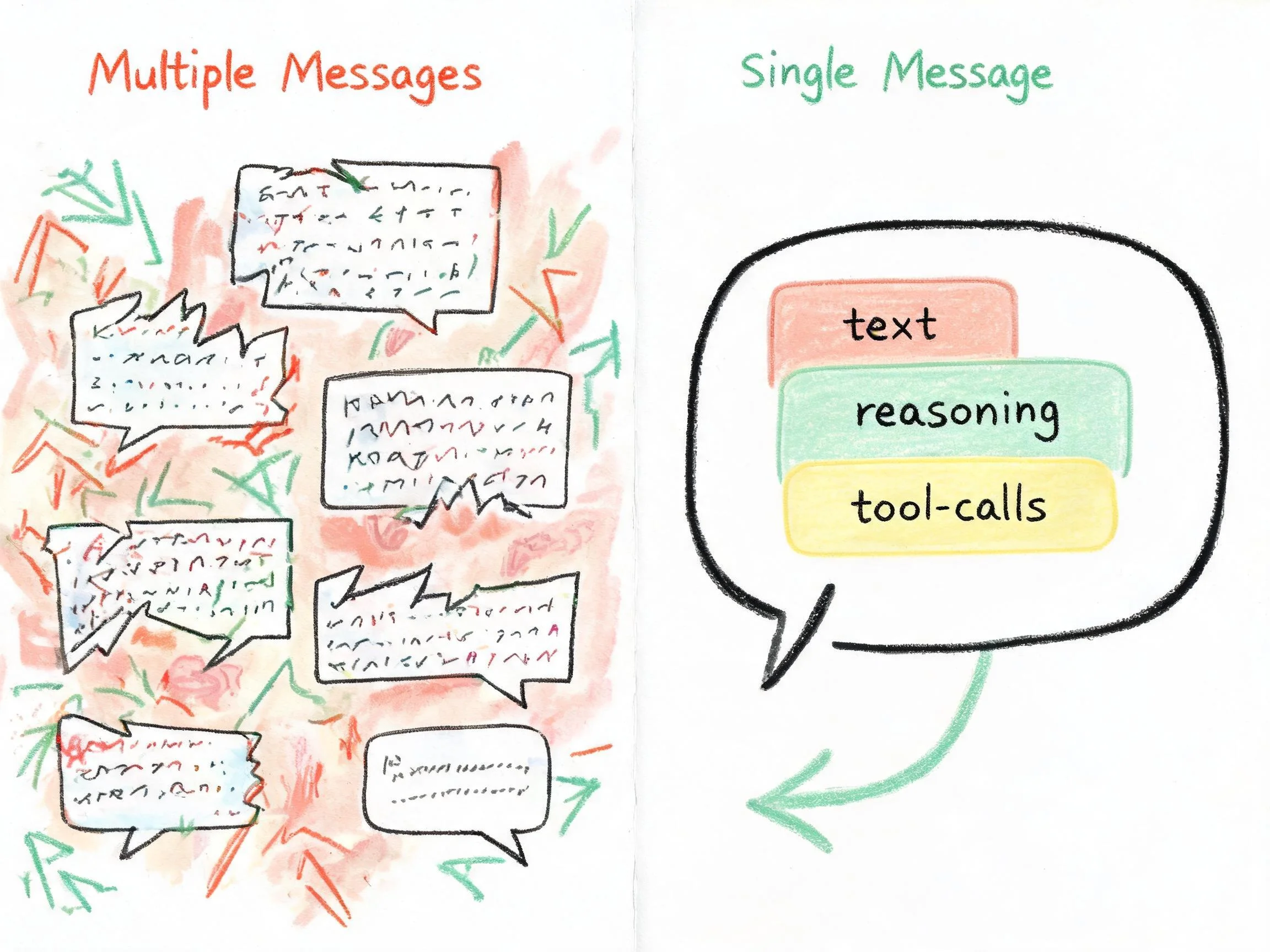
多步产出的内容,在会话里应该表现为多个 assistant message(一步一个),还是单个 assistant message(一次用户请求对应一个)?
早期我倾向于多 message,但很快遇到三个问题:
- 流式体验断裂:用户看到 assistant 回答了一半停了,又出现第二条回答,像断线重连;
- 语义不对:一次用户输入对应一次 assistant 回复,这是对话的基本单元。把一次请求拆成多个 assistant message,等于把一次思考过程摊成多轮对话;
- 下游渲染复杂:UI 要处理同一轮里的多个 assistant bubble,状态管理、打字机动画、思考块折叠都会变乱。
最终选择:一次用户输入,只产生一个 assistant message。多步 loop 的所有内容累加到同一个 message 里。
三、单 message 里的 parts
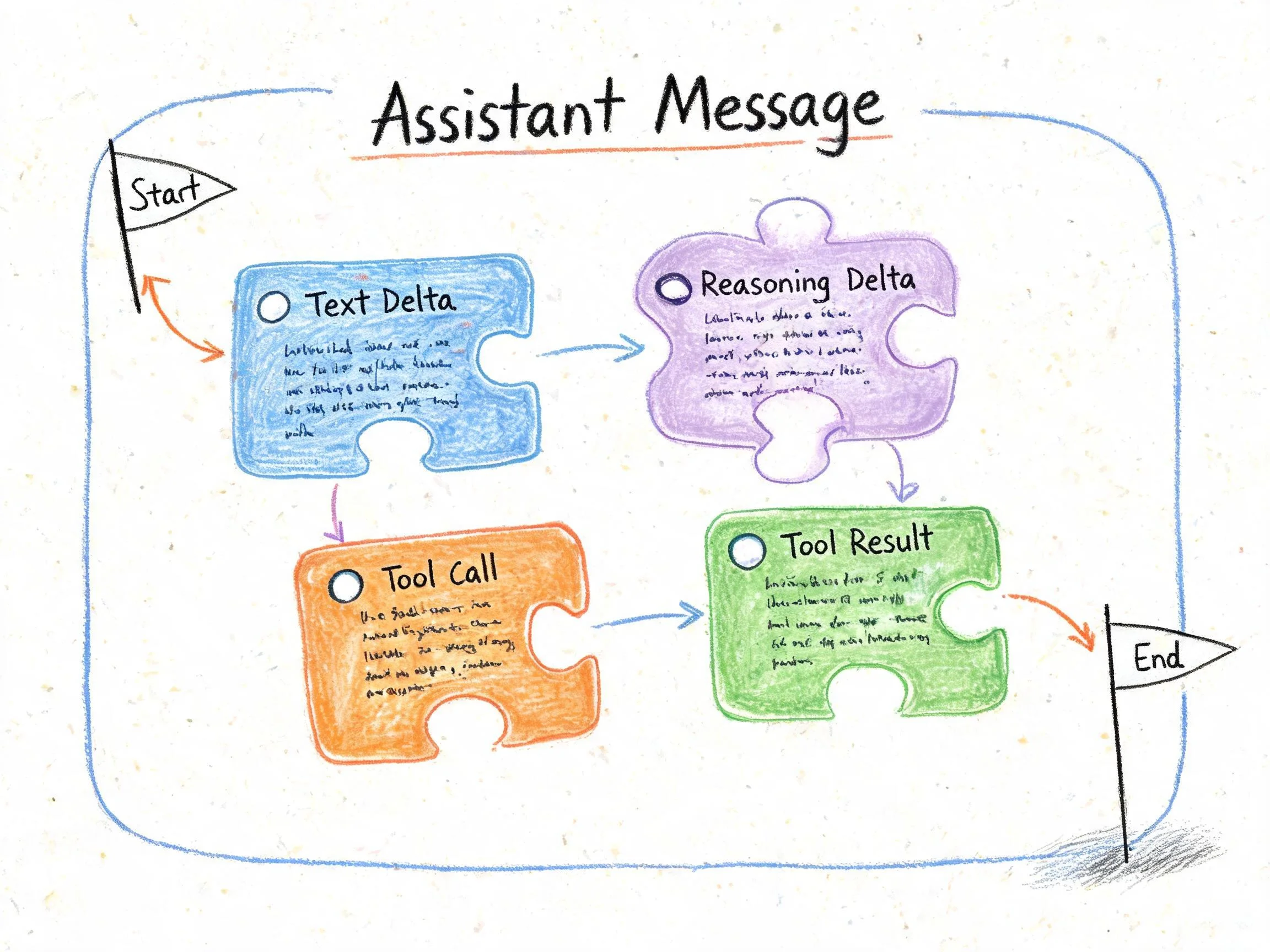
单 message 的前提是 message 内部不能只存一段字符串,要能容纳「输出文字 → 调用工具 → 拿到结果 → 再输出文字」这种交错结构。这种结构在业界通常被叫做 parts:一次模型响应由多个 part 组成,包括 text、reasoning、tool-call、tool-result。
流控制器把内部事件合成为带边界的输出块:
export type RawChunk =
| { type: 'text-delta'; step: number; text: string }
| { type: 'reasoning-delta'; step: number; text: string }
| { type: 'tool-call'; step: number; toolCallId: string; toolName: string; input: unknown }
| { type: 'tool-result'; step: number; toolCallId: string; output: string; error?: string };append 在切换内容类型时自动补全 start / finish 边界:
if (chunk.type === 'text-delta') {
this.ensurePartOpen('text', chunk.step);
this.enqueue({ type: 'text-delta', step: chunk.step, partId: this.currentPart!.partId, text: chunk.text });
}UI 拿到带边界的 chunk 后按 part 渲染:文本打字机、reasoning 折叠、tool-call 卡片。单元测试覆盖了边界顺序:text-start → text-delta → text-finish → reasoning-start → reasoning-delta → reasoning-finish → finish。
四、单 message 下维护多轮 loop 内容
turn runner 在循环时不直接加新的 assistant message,而是先创建一条空的 assistant message,每一步往里面追加内容:
const assistantMsg: ModelMessage = { role: 'assistant', content: [] } as unknown as ModelMessage;
state.addMessage(assistantMsg);
hooks.onMessageAdded(assistantMsg);loop 拿到模型输出后,把 text、reasoning、tool-call 追加到同一个 assistantMsg.content 数组。工具执行结果以 tool role 的消息加入 conversation,紧跟在同一条 assistant message 之后,不开启新的 assistant message。
一次用户请求对应的会话结构:
user
assistant ← 包含多个 parts:text / reasoning / tool-call
tool ← 工具结果
tool ← 工具结果语义清晰,对流式渲染也友好。
五、多轮会话中 parts 的还原
单 message + parts 在运行时顺畅,但多轮会话里必须解决一个问题:下一次调用模型时,parts 要还原成对应 SDK 能理解的 message 格式。
不同 Provider 格式差异很大:OpenAI 的 assistant message 是 content + tool_calls 数组;Anthropic 的 assistant message 是 content blocks,包含 text 和 tool_use;工具结果在 OpenAI 里是 role: 'tool' 且带 tool_call_id,在 Anthropic 里是 user message 里的 tool_result block。
OpenAI 适配层里的转换大致是:
function toAssistantMessage(content: unknown): OpenAI.Chat.ChatCompletionAssistantMessageParam {
if (typeof content === 'string') {
return { role: 'assistant', content };
}
const text = content
.filter((part: any) => part.type === 'text')
.map((part: any) => part.text)
.join('');
const toolCalls = content
.filter((part: any) => part.type === 'tool-call')
.map((part: any) => ({
id: part.toolCallId,
type: 'function' as const,
function: {
name: part.toolName,
arguments: JSON.stringify(part.input),
},
}));
return {
role: 'assistant',
content: text,
tool_calls: toolCalls.length > 0 ? toolCalls : undefined,
};
}Anthropic provider 把 tool-call part 映射成 tool_use block。这一步很容易出错:OpenAI 要求 assistant message 里的 tool_calls 和后面 role: 'tool' 的消息一一对应;Anthropic 要求 tool_use 的 id 和 tool_result 的 tool_use_id 对齐。
我的做法是把对内抽象和对外适配严格分开:内部状态永远用 parts;调用模型前通过 provider 做一次性还原;还原失败的问题被限制在 provider 层,不污染 core 的循环逻辑。
六、最终成型的架构
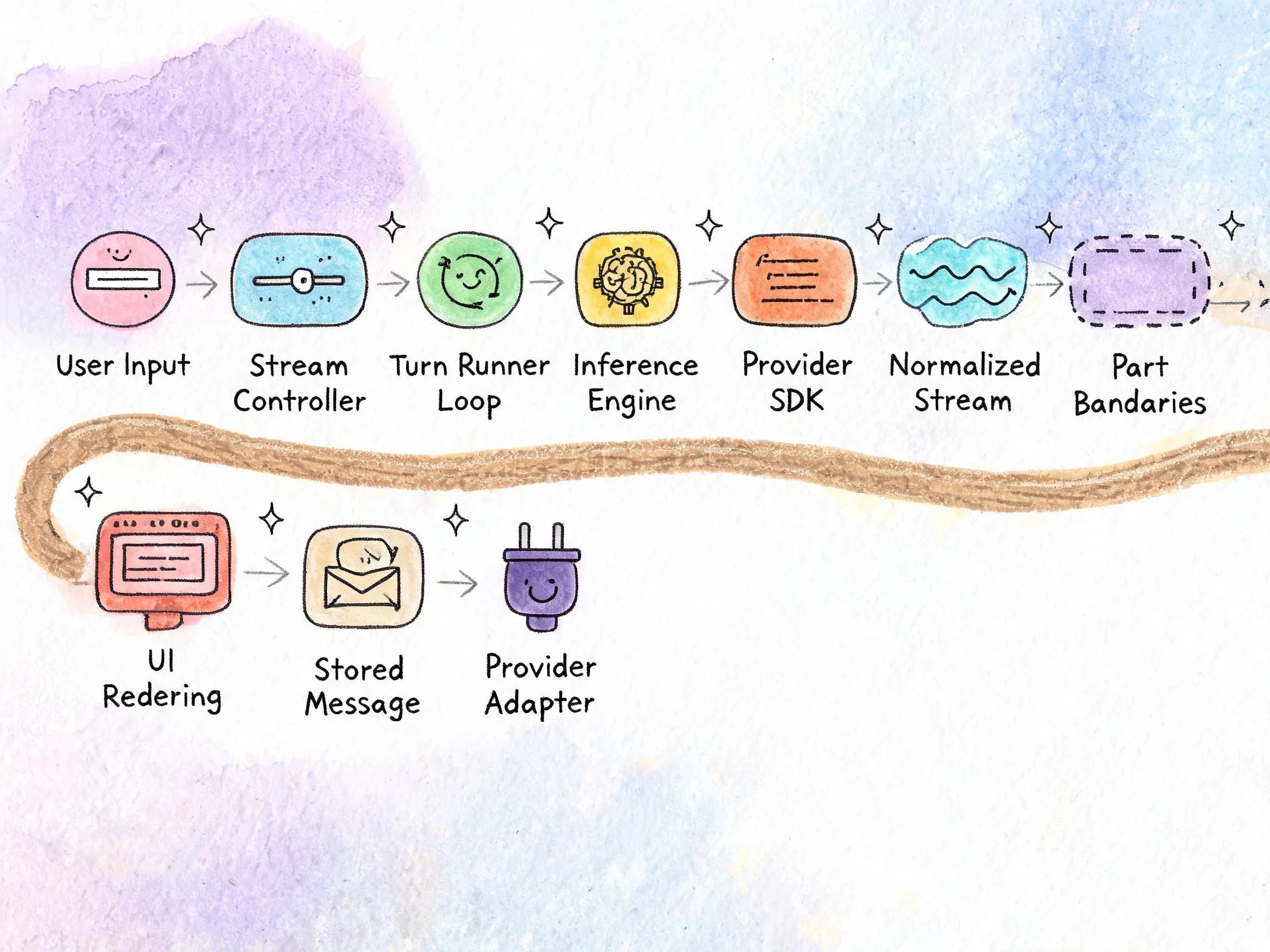
整条链路:用户输入 → 入口方法创建流控制器 → turn runner 多步循环 → loop 调用推理引擎的 infer → Provider SDK 原始流解析为 StreamChunk → 推理引擎归一化与 thinking 分区 → loop 映射为内部事件并 append → 流控制器合成 part 边界 → UI 消费 fullStream 按 part 渲染 → Turn 结束 parts 存入 assistant message → 下次调用时 provider 把 parts 还原为 SDK-specific messages。
这个架构的核心是:流式是一套贯穿 Agent 运行的事件协议。流控制器把异步事件整理成有序、可观测的 chunk;StreamChunk / OutputChunk 是统一协议;parts 是 message 内部的组织单元;provider 转换是对外适配层。
七、总结
做 Agent 流式时,常见误区是只把它当传输优化。真正决定体验的,是消息模型能不能承载一次请求内的多步结构。
每一步 loop 都生成新 message,流式会断、会话会乱、UI 会丑。坚持用单 message,就要引入 parts 抽象,并认真解决 parts 在多轮会话中的还原问题。
我的方案是:内部用 parts 统一表达,调用模型前按 provider 还原。这样既不牺牲流式体验,也不被某个 SDK 的消息格式绑架。
流式让 Agent 的中间过程变得可见。把这件事做对,关键在消息协议和循环控制是否足够清晰。